Spawn methods explained
for Ruby developers
At its core, Passenger is an HTTP proxy and process manager. It spawns application processes and forwards incoming HTTP request to one of them.
While this may sound simple, there is not just one way to spawn application processes. Passenger supports so-called "smart spawning" (currently for Ruby applications only), which leverages virtual memory copy-on-write semantics of the operating system in order to reduce overall memory usage.
This article describes the different spawning methods that Passenger has available, and how they compare to each other and how smart spawning works.
We assume that you use Ruby. If you do not use Ruby, then Passenger always uses direct spawning.
Table of contents
- Loading...
The most straightforward and traditional way: direct spawning
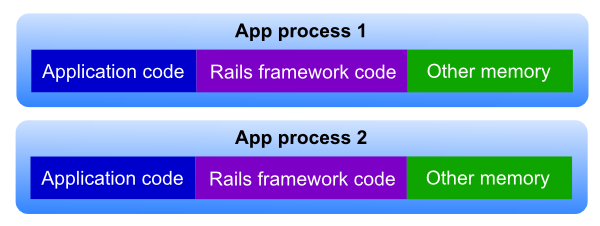
Passenger could create a new Ruby process, which will then load the web framework (e.g. Rails) along with the application code. This process then enters a request handling main loop.
This is the most straightforward way to spawn processes, and each process contains a full copy of the application code and the web framework in memory.
While this works well, it's not as efficient as it could be because each process has its own private copy of the application code as well as the web framework. This wastes memory as well as startup time.
The smart spawning method
It is possible to make the different processes share the memory occupied by application and web framework code. This is achieved by utilizing so-called copy-on-write semantics of the virtual memory system on modern operating systems. As a side effect, the startup time is also reduced. This technique is exploited by Passenger's smart spawn method.
For Ruby apps, the spawn method defaults to smart. This feature is similar to Unicorn's preload_app true feature.
How it works
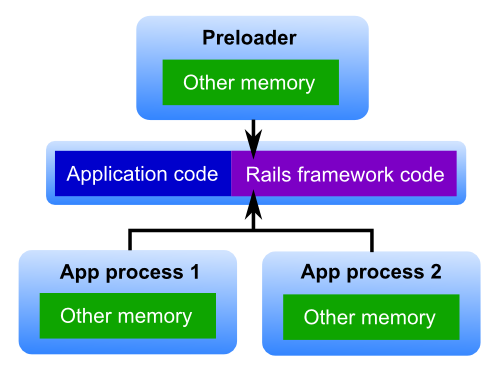
When the smart spawn method is being used, Passenger will first create a so-called 'preloader' process. This process loads the entire application along with the web framework, by loading the file config.ru. The preloader process doesn't participate in request handling.
Then, whenever Passenger needs a new application process, it will instruct the preloader to create one. The preloader then spawns a child process (with the fork() system call). The operating system guarantees that this child process is an exact virtual copy of itself. This child process therefore already has the application code and the web framework code in memory.
Creating a process like this is very fast, about 10 times faster than loading the Ruby application + framework from scratch. On top of that, the OS also applies an optimization called "copy-on-write". This means that all memory that the child process hasn't modified, is shared with the parent process.
However, Ruby can only leverage this copy-on-write optimization if its garbage collector is copy-on-write friendly. This is only the case starting from Ruby 2.0.0. Earlier versions cannot leverage copy-on-write optimizations.
Note that preloader processes have an idle timeout just like application processes. If a preloader hasn't been instructed to do anything for a while, it will be shutdown in order to conserve memory. This idle timeout is configurable.
Summary of benefits
Suppose that Passenger needs a process for an application that uses Rails 4.2.0.
If the 'smart' spawning method is used, and a preloader for this application is already running, then process creation time is about 10 times faster than direct spawning. This process will also share application and Rails framework code memory with the preloader, as well as with other processes that have been spawned by the same preloader.
In practice (and assuming you are using Ruby 2.0.0 and later), the smart spawning method saves about 33% memory on average.
Of course, smart spawning is not without caveats. But if you understand the caveats you can easily reap the benefits of smart spawning.
Smart spawning caveats
Ruby >= 2.0.0 required
Ruby can only leverage this copy-on-write optimization if its garbage collector is copy-on-write friendly. This is only the case starting from Ruby 2.0.0. Earlier versions cannot leverage copy-on-write optimizations.
Smart spawning still works on earlier Ruby versions. No error will be thrown. Using smart spawning on older Ruby versions still buys you reduced spawning time. The only benefit you don't get, is reduced memory usage.
Unintentional file descriptor sharing
Because application processes are created by forking from a preloader process, it will share all file descriptors that are opened by the preloader process. (This is part of the semantics of the Unix 'fork()' system call. You might want to Google it if you're not familiar with it.) A file descriptor is a handle which can be an opened file, an opened socket connection, a pipe, etc. If different application processes write to such a file descriptor at the same time, then their write calls will be interleaved, which may potentially cause problems.
The problem commonly involves socket connections that are unintentionally being shared. You can fix it by closing and reestablishing the connection when Passenger is creating a new application process. Passenger provides the API call PhusionPassenger.on_event(:starting_worker_process) to do so (see also Smart spawning hooks). So you could insert the following code in your config.ru:
if defined?(PhusionPassenger)
PhusionPassenger.on_event(:starting_worker_process) do |forked|
if forked
# We're in smart spawning mode.
... code to reestablish socket connections here ...
else
# We're in direct spawning mode. We don't need to do anything.
end
end
end
Note that Passenger automatically reestablishes the ActiveRecord primary database connection upon creating a new application process, which is why you normally do not encounter any database issues when using smart spawning mode.
Example 1: Memcached connection sharing (harmful)
Suppose we have a Rails application that, in its config/application.rb, calls some code which connects to a Memcached server. Since config/application.rb is loaded from config.ru, this causes the preloader to have a socket connection (file descriptor) to the Memcached server, as shown in the following figure:
+--------------------+
| Preloader |-----------[Memcached server]
+--------------------+
Suppose that Passenger then proceeds with creating a new application process, which is to process incoming HTTP requests. The result will look like this:
+--------------------+
| Preloader |------+----[Memcached server]
+--------------------+ |
|
+--------------------+ |
| App process 1 |-----/
+--------------------+
Since a fork() makes a (virtual) complete copy of a process, all its file descriptors will be copied as well. What we see here is that Preloader and App process 1 both share the same connection to Memcached.
Now supposed that your site gets a sudden large surge of traffic, and Passenger decides to spawn another process. It does so by forking Preloader. The result is now as follows:
+--------------------+
| Preloader |------+----[Memcached server]
+--------------------+ |
|
+--------------------+ |
| App process 1 |-----/|
+--------------------+ |
|
+--------------------+ |
| App process 2 |-----/
+--------------------+
As you can see, App process 1 and App process 2 have the same Memcached connection.
Suppose that users Joe and Jane visit your website at the same time. Joe's request is handled by App process 1, and Jane's request is handled by App process 2. Both application processes want to fetch something from Memcached. Suppose that in order to do that, both handlers need to send a FETCH command to Memcached.
But suppose that, after App process 1 having only sent FE, a context switch occurs, and App process 2 starts sending a FETCH command to Memcached as well. If App process 2 succeeds in sending only one byte, F, then Memcached will receive a command which begins with FEF, a command that it does not recognize. In other words: the data from both handlers get interleaved. And thus Memcached is forced to handle this as an error.
This problem can be solved by reestablishing the connection to Memcached after forking:
+--------------------+
| Preloader |------+----[Memcached server]
+--------------------+ | |
| |
+--------------------+ | |
| App process 1 |-----/| |
+--------------------+ | | <--- created this
X | new
| connection
X <-- closed this |
+--------------------+ | old |
| App process 2 |-----/ connection |
+--------------------+ |
| |
+-------------------------------------+
App process 2 now has its own, separate communication channel with Memcached. The code in config.ru looks like this:
if defined?(PhusionPassenger)
PhusionPassenger.on_event(:starting_worker_process) do |forked|
if forked
# We're in smart spawning mode.
reestablish_connection_to_memcached
else
# We're in direct spawning mode. We don't need to do anything.
end
end
end
Example 2: log file sharing (not harmful)
There are also cases in which unintentional file descriptor sharing is not harmful. One such case is log file file descriptor sharing. Even if two processes write to the log file at the same time, the worst thing that can happen is that the data in the log file is interleaved.
To guarantee that the data written to the log file is never interleaved, you must synchronize write access via an inter-process synchronization mechanism, such as file locks. Reopening the log file, like you would have done in the Memcached example, doesn't help.
The need to revive threads
Another part of the fork() system call's semantics is the fact that threads disappear after a fork call. So if you've created any threads in environment.rb, then those threads will no longer be running in newly created application process. You need to revive them when a new process is created. Use the :starting_worker_process event that Passenger provides, like this:
if defined?(PhusionPassenger)
PhusionPassenger.on_event(:starting_worker_process) do |forked|
if forked
# We're in smart spawning mode.
... code to revive threads here ...
else
# We're in direct spawning mode. We don't need to do anything.
end
end
end
Smart spawning hooks
You can hook into the smart spawning mechanism as follows.
If you want any code to be executed before the preloader has forked any child processes, then call that code in config.ru (or from any code called while loading config.ru, such as config/application.rb).
If you want any code to be executed after the preloader has forked a child process, and you want that code to be run in the context of the child process, then use the :starting_worker_process hook that Passenger provides. Put the following code in config.ru (or from any code called while loading config.ru, such as config/application.rb):
if defined?(PhusionPassenger)
PhusionPassenger.on_event(:starting_worker_process) do |forked|
if forked
# We're in smart spawning mode.
... your code here ...
else
# We're in direct spawning mode. We don't need to do anything.
end
end
end
The forked argument is true if and only if Passenger spawned the app in smart spawning mode.
This hook is comparable to the Unicorn after_fork hook.
Smart spawning FAQ
I'm running into a problem. Is it caused by smart spawning?
Try disabling smart spawning (which means using direct spawning). If disabling smart spawning didn't help, then it is 100% certain that whatever problem you had, is not related to smart spawning.
If disabling smart spawning did help, then please go over the smart spawning caveats.
Smart spawning can be disabled as follows:
| Nginx | passenger_spawn_method direct; |
| Apache | PassengerSpawnMethod direct |
| Standalone | --spawn-method direct |
Am I responsible for reestablishing database connections after the preloader has forked a child process?
It depends. Passenger automatically reestablishes the ActiveRecord primary database connection. The vast majority of Rails only uses ActiveRecord (not any other database libraries), and only with a single database connection.
If your application uses any database libraries besides ActiveRecord, OR you use ActiveRecord with more than one database connection, then you are responsible for reestablishing all connections after forking. Use the smart spawning hooks.



