

1. Introduction
1.1. Web application models and the role of the application server
Before we describe Phusion Passenger, it is important to understand how typical web applications work from the viewpoint of someone who wants to connect a web application to a web server.
A typical, isolated, web application accepts an HTTP request from some I/O channel, processes it internally, and outputs an HTTP response, which is sent back to the client. This is done in a loop, until the application is commanded to exit. This does not necessarily mean that the web application speaks HTTP directly: it just means that the web application accepts some kind of representation of an HTTP request.
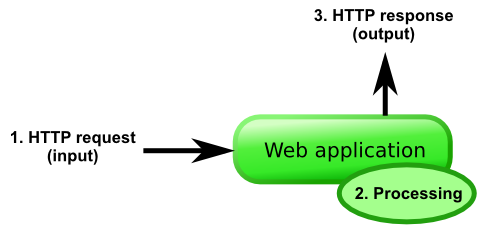
Some web applications are directly accessible through the HTTP protocol, while others are not. It depends on the language and framework that the web application is built on. For example, Ruby (Rack/Rails) and Python (WSGI) web applications are typically not directly accessible through the HTTP protocol. On the other hand, Node.js web applications do tend to be accessible through the HTTP protocol. The reasons for this are historical, but they’re outside the scope of this guide.
1.1.1. Common models
Here are some common models that are in use:
-
The web application is contained in an application server. This application server may or may not be able to contain multiple web applications. The administrator then connects the application server to a web server through some kind of protocol. This protocol may be HTTP, FastCGI, SCGI, AJP or whatever. The web server dispatches (forwards) requests to the application server, which in turn dispatches requests to the correct web application, in a format that the web application understands. Conversely, HTTP responses outputted by the web application are sent to the application server, which in turn sends them to the web server, and eventually to the HTTP client.
Typical examples of such a model:
-
A J2EE application, contained in the Tomcat application server, reverse proxied behind the Apache web server. Tomcat can contain multiple web applications in a single Tomcat instance.
-
Most Ruby application servers besides Phusion Passenger (Thin, Unicorn, Goliath, etc). These application servers can only contain a single Ruby web application per instance. They load the web application into their own process and are put behind a web server (Apache, Nginx) in a reverse proxy setup.
-
Green Unicorn, the Python (WSGI) application server, behind a reverse proxy setup.
-
PHP web applications spawned by the FastCGI Process Manager (FPM), behind an Nginx reverse proxy setup.
-
-
The web application is contained directly in a web server. In this case, the web server acts like an application server. Typical examples include:
-
PHP web applications running on Apache through mod_php.
-
Python (WSGI) web applications running on Apache through mod_uwsgi or mod_python.
Note that this does not necessarily mean that the web application is run inside the same process as the web server: it just means that the web server manages applications. In case of mod_php, PHP runs directly inside the Apache worker processes, but in case of mod_uwsgi the Python processes can be configured to run out-of-process.
Phusion Passenger for Apache and Phusion Passenger for Nginx implement this model, and run applications outside the web server process.
-
-
The web application is a web server, and can accept HTTP requests directly. Examples of this model:
-
Almost all Node.js and Meteor JS web applications.
-
The Trac bug tracking software, running in its standalone server.
In most setups, the administrator puts them in a reverse proxy configuration, behind a real web server such as Apache or Nginx, instead of letting them accept HTTP requests directly.
Phusion Passenger Standalone implements this model. However, you can expose Phusion Passenger Standalone directly to the Internet because it uses Nginx internally.
-
-
The web application does not speak HTTP directly, but is connected directly to the web server through some communication adapter. CGI, FastCGI and SCGI are good examples of this.
The above models cover how nearly all web applications work, whether they’re based on PHP, Django, J2EE, ASP.NET, Ruby on Rails, or whatever. Note that all of these models provide the same functionality, i.e. no model can do something that a different model can’t. The critical reader will notice that all of these models are identical to the one described in the first diagram, if the combination of web servers, application servers, web applications etc. are considered to be a single entity; a black box if you will.
It should also be noted that these models do not enforce any particular I/O processing implementation. The web servers, application servers, web applications, etc. could process I/O serially (i.e. one request at a time), could multiplex I/O with a single thread (e.g. by using select(2) or poll(2)) or it could process I/O with multiple threads and/or multiple processes. It depends on the implementation.
Of course, there are many variations possible. For example, load balancers could be used. But that is outside the scope of this document.
1.1.2. The rationale behind reverse proxying
As you’ve seen, administrators often put the web application or its application server behind a real web server in a reverse proxy setup, even when the web app/app server already speaks HTTP. This is because implementing HTTP in a proper, secure way involves more than just speaking the protocol. The public Internet is a hostile environment where clients can send any arbitrary data and can exhibit any arbitrary I/O patterns. If you don’t properly implement I/O handling, then you could open yourself either to parser vulnerabilities, or denial-of-service attacks.
Web servers like Apache and Nginx have already implemented world-class I/O and connection handling code and it would be a waste to reinvent their wheel. In the end, putting the application in a reverse proxying setup often makes the whole system more robust and and more secure. This is the reason why it’s considered good practice.
A typical problem involves dealing with slow clients. These clients may send HTTP requests slowly and read HTTP responses slowly, perhaps taking many seconds to complete their work. A naive single-threaded HTTP server implementation that reads an HTTP requests, processes, and sends the HTTP response in a loop may end up spending so much time waiting for I/O that spends very little time doing actual work. Worse: suppose that the client is malicious, just leaves the socket open and never reads the HTTP response, then the server will spend forever waiting for the client, not being able to handle any more requests. A real-world attack based on this principle is Slowloris.
while true
client = accept_next_client()
request = read_http_request(client)
response = process_request(request)
send_http_response(client, response)
end
There are many ways to solve this problem. One could use one thread per client, one could implement I/O timeouts, one could use an evented I/O architecture, one could have a dedicated I/O thread or process buffer requests and responses. The point is, implementing all this properly is non-trivial. Instead of reimplementing these over and over in each application server, it’s better to let a real web server deal with all the details and let the application server and the web application do what they’re best at: their own core business logic.
1.2. Phusion Passenger architecture overview
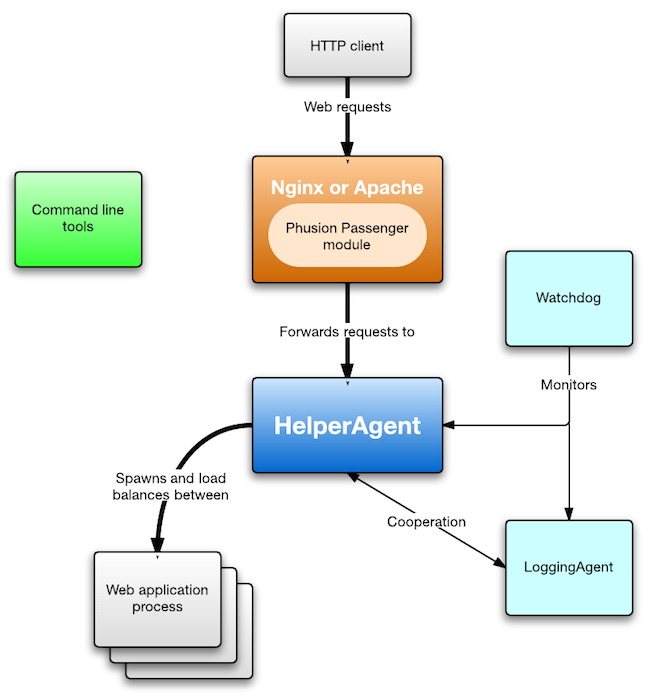
Phusion Passenger is not a single, monolithic entity. Instead, it consists of multiple components and processes that work together. Part of the reason why Phusion Passenger is split like this, is because it’s technically necessary (no other way to implement it). But another part of the reason is stability and robustness. Individual components can crash and can be restarted independently from each other. If we were to put everything inside a single process, then a crash will take down all of Phusion Passenger.
Thus, if the Passenger core crashes, or if an application process crashes, they can both be restarted without affecting the web server’s stability.
1.2.1. Web server module
When an HTTP client sends a request, it is received by the web server (Nginx or Apache). Both Apache and Nginx can be extended with modules. Phusion Passenger provides such a module. The module is loaded into Nginx/Apache. It checks whether the request should be handled by a Phusion Passenger-served web application, and if so, forwards the request to the Passenger core. The internal wire protocol used during this forwarding, is a modified version of SCGI.
The Nginx module and Apache module have an entirely different code base. Their code bases are in ext/nginx and ext/apache2, respectively. Both modules are relatively small because they outsource most logic to the Passenger core, and because they utilize a common library (ext/common). This allows us to support both Nginx and Apache without having to write a lot of things twice.
1.2.2. Passenger core
The Passenger core is where most of the processing is done. The core keeps track of which application processes currently exist, and using load balancing rules, determines which process a request should be forwarded to. The core also takes care of application spawning: if it determines that having more application processes is necessary or beneficial, then it will make that happen. Process spawning is subject to user-configured limits: the core will never spawn more processes than a user-configured maximum.
The core also has monitoring and statistics gathering capabilities. It constantly keeps track of applications' memory usage, how many requests they’ve handled, etc. This information can later be queried from administration tools. And if an application process crashes, the core restarts it.
The core is by far the largest and most complex part of the system, but it is itself composed of several smaller subsystems. Most of the core architecture chapter is devoted to describing the core.
1.2.3. UstRouter
The core cooperates with the UstRouter. This latter is responsible for sending data to Union Station, a monitoring web service. If you didn’t explicitly tell Phusion Passenger to send data to Union Station, then the UstRouter sits idle and does not consume resources.
1.2.4. Watchdog
The core and the UstRouter contain complex logic, so they could contain bugs which could crash them. So as a safety measure, they are both monitored by the Watchdog. If either of them crash, they are restarted by the Watchdog. This setup seeks to ensure that the system stays up, no matter what.
You might now wonder: what happens if the Watchdog crashes? Shouldn’t the Watchdog be monitored by another Watchdog? We’ve contemplated this possibility, but the Watchdog is very simple, and since 2012 we haven’t seen a single report of the Watchdog crashing, nor have we been able to make it crash since that time. So, for the sake of keeping the codebase as simple as possible, we’ve chosen not to introduce multiple Watchdogs.
1.2.5. Command line tools
Finally, there is an array of command line tools which support Phusion Passenger. The installers — passenger-install-*-module — are responsible for installing Phusion Passenger. There are administrative tools such as passenger-status and passenger-memory-stats. And many more. Some of these tools may communicate with one of the agents. For example, the passenger-status queries the core for information that the core has collected. How this communication is done, is described in Instance state and communication.
1.2.6. Passenger Standalone
You might have noticed that Phusion Passenger Standalone is not part of the diagram. So how does it fit into the architecture? Well, Phusion Passenger Standalone is actually just Phusion Passenger for Nginx. The passenger start command simply sets up a modified and stripped-down Nginx web server (which we call the WebHelper) with the Phusion Passenger Nginx module loaded.
1.3. Build system and source tree
Phusion Passenger is written mostly in C++ and Ruby. The web server modules, core, UstRouter and Watchdog are written in C++. Most command line tools are written in Ruby. You can find each component here:
-
The web server modules can be found in ext/apache2 and ext/nginx.
-
The Passenger core, UstRouter and Watchdog can be found in ext/common/agent.
-
The command line tools can be found in bin, with some parts of their code in lib.
More information can be found in the Contributors Guide. This guide also teaches you how to compile Phusion Passenger.
2. Initialization
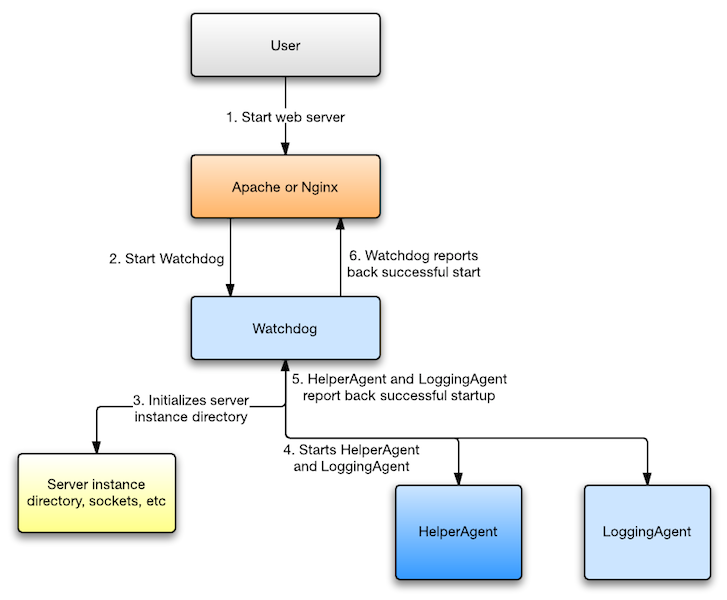
Phusion Passenger initializes as follows.
-
First, the user begins with starting the web server. This for example be done by running sudo service apache2 start or sudo service nginx start. Or perhaps the web server is configured to be automatically started by the OS, in which case the user doesn’t have to do anything. In case of Phusion Passenger Standalone, the user runs passenger start which in turn starts Nginx.
-
The Phusion Passenger module inside Nginx/Apache proceeds with starting the Watchdog. This is implemented in:
-
ext/nginx/ngx_http_passenger_module.c, function start_watchdog().
-
ext/apache2/Hooks.cpp, in the constructor for the Hooks class.
-
ext/common/AgentsStarter.h and AgentsStarter.cpp. Most of the logic pertaining starting the Watchdog is in this file.
-
-
The Watchdog first initializes a "instance directory", which is a temporary directory containing files that will be used during the life time of this Phusion Passenger instance. For example, the directory contains Unix domain socket files, so that the different Phusion Passenger processes can communicate with each other. The Watchdog is implemented in ext/common/agent/Watchdog/Main.cpp.
-
The Watchdog starts the Passenger core and the UstRouter simultaneously. Each performs its own initialization.
-
When the core is done initializing, it will send a message back to the Watchdog saying that it’s done. The UstRouter does something similar. When the Watchdog has received both acknowledgment messages, it finishes initialization. If the Watchdog notices that one of the agents have exited without sending an acknowledgment message, then it enters an error state.
-
The Watchdog reports successful startup back to the Phusion Passenger module that’s running inside Nginx/Apache. Or, if initialization didn’t success, the Watchdog reports back an error. The Phusion Passenger module inside Nginx/Apache then logs the error.
After initialization, Phusion Passenger is ready to receive and to process requests.
3. Passenger core architecture
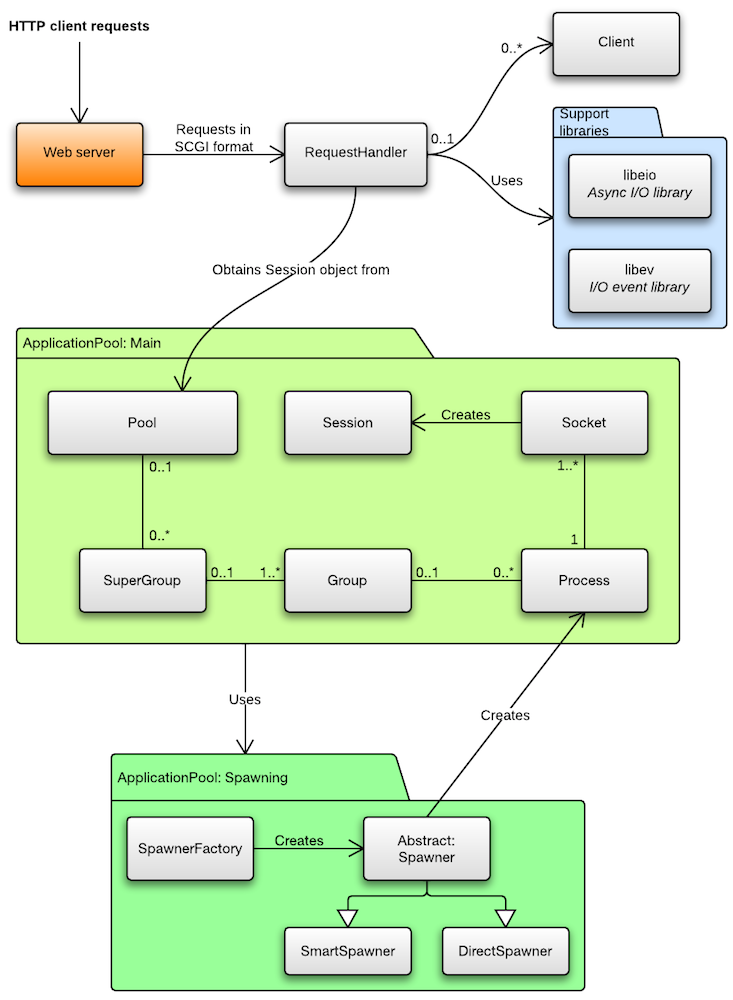
The Passenger core consists of two subsystems. One is the request handling subsystem. The other is the ApplicationPool subsystem, which performs the bulk of process management. The core also uses a number of support libraries. The largest third-party support libraries are shown in the diagram. Many more — internal — support libraries are used, but they’re omitted from the diagram. You can find these internal support libraries in the directory ext/common/Utils.
3.1. Request handling
Recall that requests are first received from the web server. The web server serializes the request into a slightly modified version of the SCGI format, and sends it to the core’s RequestHandler. The RequestHandler performs some work, and eventually sends back a regular HTTP response. The web server parses the RequestHandler response, and sends a response to the original HTTP client.
The RequestHandler listens on a Unix domain socket file. This Unix domain socket file is called request, and is located in the instance directory.
3.1.1. One client per request
The web server creates a new connection to the core on every request. Thus, from the viewpoint of the RequestHandler, its client is the web server. Every time a client connects (i.e. a new request is forwarded), the RequestHandler creates a new Client object which represents that request. All request-specific state is stored inside the Client. After the RequestHandler is done processing a request, it closes the client socket.
Note that in the diagram, a Client has a 0..1 association with RequestHandler. That’s because when a Client is disconnected, the pointer to the associated RequestHandler is set to NULL. There might be background operations left which still have a pointer to the Client. As soon as those background operations finish, they check whether the Client has a valid pointer to the RequestHandler. If so, they commit their work; if not, they discard their work. The Client is destroyed when all its associated background operations have finished.
3.1.2. Forwarding to the application
The RequestHandler asynchronously asks the ApplicationPool subsystem to select an appropriate application process to handle this request. The ApplicationPool checks whether there is an appropriate process, and if not, tries to spawn one. Maybe spawning is not possible right now because of configured resource limits, and we have to wait. In any case, the ApplicationPool takes care of all the nasty details and book keeping, and eventually replies back to the RequestHandler with either a Session object, or an exception.
A Session object represents a single request/response cycle with a particular application process. The RequestHandler uses the information in this Session object to establish a connection with that process and forwards the request, using a protocol that the application prefers and that the RequestHandler supports. The process performs work, and replies back with an HTTP response. The RequestHandler parses and postprocesses the response, and sends a response back to the web server.
If the ApplicationPool replied with an exception, the RequestHandler sends back an error response.
3.1.3. I/O model
The RequestHandler uses the evented I/O model. This means that the RequestHandler handles many clients (requests) at the same time, using a single thread, inside a single process. This is possible through the use of I/O event multiplexing mechanisms, which are provided by the OS. Examples of such mechanisms include the select(), poll(), epoll() and kqueue() system calls. But those mechanisms are very low-level and OS-specific, so the RequestHandler uses two libraries which abstract away the differences and provide a higher-level API: libev and libuv.
The evented I/O model is also used in Nginx. It is in contrast to the single-threaded multi-process model which handles 1 client per process (used by Apache with the prefork MPM), or the multi-threaded model which handles 1 client per thread (used by Apache with the worker MPM). You can learn more about evented I/O and the different I/O models through these resources:
-
Event-Driven I/O: A hands-on introduction — Marc Seeger, 2010
-
Event Driven IO And Blocking vs NonBlocking — Stack Overflow
-
How does event driven I/O allow multiprocessing? — Stack Overflow
-
The C10K problem — an overview of the different I/O models used in different servers; Dan Kegel
3.2. The ApplicationPool subsystem
The ApplicationPool subsystem is responsible for:
-
Keeping track of which application processes exist.
-
Spawning processes.
-
Routing requests to an appropriate process. This also implies that it load balances requests between processes.
-
Monitoring processes (CPU usage, memory usage, etc).
-
Enforcing resource limits. Ensuring that not too many processes are spawned, ensuring that processes that use too much memory are shut down, etc.
-
Restarting processes on demand (e.g. when the timestamp of restart.txt has changed).
-
Restarting processes that have crashed.
-
Queuing requests and limiting concurrency. Each process tells the ApplicationPool how many concurrent requests it can handle. If more concurrent requests come in than the processes says it can handle, then the excess requests are queued within the ApplicationPool subsystem. Similarly, if requests come in while a process is being spawned, then those requests are queued until the process is done spawning.
The main interface into the subsystem is the Pool class, with its asyncGet() method. The RequestHandler calls something like pool->asyncGet(options, callback) inside its checkoutSession() method. asyncGet() replies with a Session, or an exception.
The Pool class is the core of the subsystem. It contains high-level process management logic but not low-level details, such as the details of spawning processes. The code is further divided into the following classes, each of which contain the core code managing its respective domain:
- Group
-
Represents an application. It can contain multiple processes, all belonging to the same application.
- Process
-
Represents an OS process; an instance of a certain application. A process may have multiple server sockets on which it listens for requests. The Process class contains various book keeping information, such as the number of sessions that are currently open. It also contains the communication channel with the underlying OS process. Process objects are created through the ApplicationPool Spawner sub-subsystem.
- Socket
-
Represents a single server socket, on which a process listens for requests. Session objects are created through Socket. Socket maintains book keeping information about how many sessions are currently open for that particular socket.
- Session
-
Represents a single request/response cycle with a particular process. Upon creation and destruction, various book keeping information is updated.
- Options (not shown in diagram)
-
A configuration object for the Pool::asyncGet() method.
If you look at the diagram, then you see that Group and Process all have 0..1 associations with their containing classes. An object that has a NULL association with its containing object, is considered invalid and should not be used. The fact that the association can be NULL is a detail of the memory management scheme that we employ.
3.3. The Spawner subsystem
The Spawner subsystem is a sub-subsystem within ApplicationPool. It is responsible for actually spawning application processes, and then creating Process objects with the correct information in it.
The Spawner interface encapsulates all low-level process spawning logic. Pool calls Spawner whenever it needs to spawn another application process.
Recall that Phusion Passenger supports multiple spawn methods. For example, the smart spawn method spawns processes through an intermediate preloader process, and can utilize copy-on-write. This is explained in detail in Spawn methods explained in the Phusion Passenger manual. Each spawn method corresponds to a different implementation of the Spawner interface. The following implementations are available:
-
DirectSpawner — implements the direct spawn method.
-
SmartSpawner — implements the smart spawn method.
-
DummySpawner (not shown in diagram) — only used in unit tests.
The spawn method is user-configurable through the spawnMethod field in the Options object. To avoid convoluting the Pool code with spawner implementation selection logic, we also have a SpawnerFactory class, which the Pool uses.
The details of the spawning process is described in Application spawning and loading.
4. Application spawning and loading
Application processes are spawned from the Passenger core process. Spawning a process involves a lot of preparation work, such as setting up communication channels, setting up the current working directory, environment variables, etc. This preparation work is done by a Spawner object, together with various support executables.
When preparation is done, your application’s entry point has to be loaded somehow. That loading is done through a language-specific loader program. The loader program communicates with the Spawner through the communication channel that was set up earlier, initializes the language-specific environment, sets up a server, and reports back to the Spawner. This communication is done through a certain protocol.
4.1. Preparation work
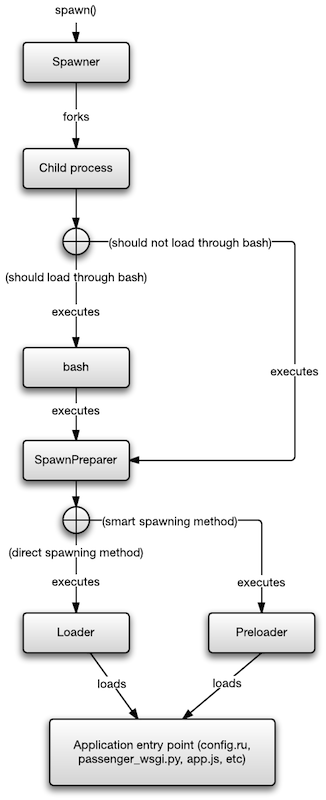
4.1.1. Basic setup and forking
Spawning begins when the spawn() method is called on a Spawner object. The Spawner determines which user the process should run as, and sets up some communication channels (anonymous Unix domain socket pairs), and forks a process. The parent waits until the child exits, or replies with something over the communication channel.
The communication channel in question is — from the viewpoint of the (pre)loader — actually just stdin, stdout and stderr! The anonymous Unix domain socket pairs that the Spawner creates, is mapped to the child process’s stdin, stdout and stderr file descriptors. Thus, Spawner sends data to the (pre)loader by writing stuff to its stdin, and the (pre)loader sends data back to the Spawner by writing stuff to stdout or stderr.
4.1.2. Loading SpawnPreparer, possibly through bash
Because the Passenger core is heavily multi-threaded, the child process has been forked by the Spawner may only perform async-signal-safe operations:
— The Open Group's POSIX specification
Don’t worry if you don’t know what this means. The point is, there’s almost nothing the forked process can safely do at that stage. So it outsources most of the remaining preparation work to an external executable, the SpawnPreparer. The SpawnPreparer starts with a clean environment where it can safely execute code.
To execute the SpawnPreparer, the child process executes one of the following commands:
-
If the target user’s shell is bash, and the passenger_load_shell_envvars option is turned on:
bash -l -c '/path-to/SpawnPreparer /path-to-loader-or-preloader'
This causes bash to load its startup files, e.g. bashrc, profile, etc, after which it executes the SpawnPreparer with the given parameters. The reason why we do this is because a lot of users try to set environment variables in their bashrc, and they expect these environment variables to be picked up by applications spawned by Phusion Passenger. Unfortunately environment variables don’t work that way, but we support it anyway because it is good for usability.
-
Otherwise, the SpawnPreparer is executed directly, without bash:
/path-to/SpawnPreparer /path-to-loader-or-preloader
How path-to-loader-or-preloader is determined, is described in The AppTypes registry.
4.1.3. SpawnPreparer further sets up the environment
The SpawnPreparer is responsible for setting up certain environment variables, current working directory, and other process environmental conditions. When SpawnPreparer is done, it executes the loader or the preloader.
4.1.4. Executing the loader or preloader
If passenger_spawn_method is set to smart (the default), and there is a preloader available for the application’s programming language, then this step executes the language-specific preloader. If either of the previous conditions are not met (and thus the passenger_spawn_method is automatically forced to direct), then this step executes the language-specific loader.
All (pre)loaders are located in the helper-scripts directory in the source tree. Here are some of the (pre)loaders that are used:
| Language/Framework | Loader | Preloader |
|---|---|---|
Ruby Rack and Rails |
rack-loader.rb |
rack-preloader.rb |
Python |
wsgi-loader.py |
- |
Node.js and bundled Meteor |
node-loader.js |
- |
Unbundled Meteor |
meteor-loader.rb |
- |
The AppTypes registry keeps a list of available (pre)loaders, and which languages they belong to.
What the loader does is described in Loaders. Likewise, preloaders are described in Preloaders.
4.2. Loaders
A loader initializes in 4 stages:
-
It first goes through a handshake, where it reads the parameters that the Spawner has sent over the communication channel.
-
It loads the application. The behavior of this stage may be customized by the received parameters.
-
It sets up a server, on which this application process listens for requests.
-
It sends a response back to the Spawner, in which it tells Spawner whether initialization was successful, and if so, where the socket is on which this application process listens for requests.
Once initialized, the loader enters a main loop, in which it keeps handling requests until a signal has been received that says it should terminate.
As explained in Basic setup and forking, the communication channels that the loader uses are just plain old stdin and stdout. Every programming language supports reading and writing from these channels. This also means that you can easily test a loader by simply executing it and entering messages in the terminal.
But stdout can also be used for printing normal output. How does the Spawner distinguish between control messages, and normal messages that should be displayed? The answer is that control messages must start with `!> ` (including the trailing whitespace), and must end with a newline. The Spawner reads messages line-by-line, processes lines that start with `!> `, and prints lines that don’t start with that marker.
4.2.1. Handshake
The handshaking process begins with a protocol version handshake. The loader printing the line !> I have control 1.0. The Spawner then sends "You have control 1.0", which the loader checks. If the loader observes that the version handshake does not match the expectation, then it aborts with an error.
The Spawner also sends a list of key-value pairs, which is terminated by an empty newline. Upon receiving the empty newline, the Spawner proceeds with loading the application.
Example:
Loader Spawner
!> I have control 1.0
You have control 1.0
passenger_root: ...
passenger_version: 4.0.45
ruby_libdir: /Users/hongli/Projects/passenger/lib
generation_dir: /tmp/passenger.1.0.2082/generation-0
gupid: 1647ad4-ovJJMiPkAAt
connect_password: jXGaSzo8vRX5oGe2uuSv5tJsf1uX7ZgIeEH2x0nfOEa
app_root: /Users/hongli/Sites/rack.test
startup_file: config.ru
process_title: Passenger RackApp
log_level: 3
environment: development
base_uri: /
...
(empty newline)
4.2.2. Application loading
How the application is loaded, depends on the programming language. Here are some examples:
-
The Ruby Rack loader does it by load()-ing the startup file, which by default is config.ru.
-
The Python loader does it by calling imp.load_source('passenger_wsgi', 'passenger_wsgi.py').
-
The Node.js (and bundled Meteor) loader does it by require()-ing the startup file, which by default is app.js.
-
The unbundled Meteor loader does it by executing the meteor run command.
If no errors occur, the loader proceeds with setting up a server. Otherwise, it reports an error.
4.2.3. Setting up a server
The loader sets up a server on which the application listens for requests. The Spawner doesn’t care how this is done, how this server works, or even what its concurrency is. It only cares about how it can contact the server. So the loader has full freedom in this step.
As explained in section Request handling and subsection Forwarding to the application, the RequestHandler can talk with the application process in a protocol that the application prefers. The RequestHandler supports two protocols:
-
A Phusion Passenger internal protocol which we call the session protocol. This protocol is used by the Ruby loaders and the Python loader. A description of this protocol is outside the scope of this document, but if you’re interested in how it looks like and how it behaves, you can study the source code of the Ruby and Python loaders, as well as ext/common/Utils/MessageIO.h.
-
The HTTP protocol. This protocol is used by the Node.js and Meteor loaders. If you’re writing a new loader then, it’s probably easiest to use this protocol, together with whatever HTTP library is available for the loader’s target language.
Typically, the server is setup to listen on a Unix domain socket file, inside the backends subdirectory of the generation directory. The path to the generation directory was passed during handshake. However the server may also listen on a TCP socket.
Once a server has been setup, the loader can report readiness.
4.2.4. Reporting readiness
Once the server is set up, the loader sends back a !> Ready response, followed by information about where the server socket listens on, and what protocol it expects. The response is terminated with a `!> ` line (notice the trailing whitespace, which is required).
The information about where the server socket listens on, is a 4-tuple:
-
The name. This must always be main.
-
The address. For Unix domain sockets, it has the form unix:/path-to-socket. For TCP socket, it has the form tcp://127.0.0.1:PORT.
-
The protocol. This must be either session or http_session.
-
The maximum number of concurrent connections the server supports. The ApplicationPool will ensure that the process never receives more concurrent requests than this number. A value of 0 means that the concurrency is unlimited.
Here’s an example of what the Node.js loader sends as response:
!> Ready !> socket: main;unix:/path-to-generation-dir/backends/node.1234-5677;session;0") !>
After reporting readiness, the loader can enter a main loop and wait for termination.
4.2.5. Error reporting
If something goes wrong in any of the stages, the loader can report an error in two ways:
-
Just write the error message to stdout as you normally do, and abort without printing the !> Ready message. The Passenger core will read everything that the loader has written to stdout, and use it as the error message. This error message is considered to be plain text.
-
Abort after printing a special !> Error message. The loader can signal that the message is HTML. The RequestHandler will format the error message as HTML.
4.2.6. Main loop and termination
The loader’s main loop’s job is to wait until a single byte has been received on stdin. As long as the byte has not been received, the loader should not exit, and should keep processing requests. When the byte has been received, the following conditions are guaranteed to be true:
-
All clients for this particular process have disconnected.
-
No more clients will be routed to this particular process.
This guarantee is enforced by the RequestHandler and the ApplicationPool. Thus, the loader doesn’t have to perform any kind of complicated shutdown. It can just exit the process.
If the server was listening on a Unix domain socket file, then the loader doesn’t even have to remove the file. The ApplicationPool already takes care of that.
4.2.7. Stdout and stderr forwarding
All lines that the loader writes to stdout, and that are not prefixed with `!> `, are forwarded by the Passenger core to its own stdout. Similarly, everything that the loader writes to stderr, whether prefixed with `!> ` or not, is forwarded by the Passenger core to its own stdout.
While the Spawner is still doing its work, it takes care of this forwarding by itself. Once the Spawner is done, it outsources this work to two PipeWatcher objects, each which spawns a background thread for this purpose.
4.3. Preloaders
Preloaders are a special kind of loaders, used for reducing spawn time and leveraging copy-on-write. You can learn more about this at Spawning methods explained.
Preloaders look a lot like loaders, but behave slightly differently. They also use stdin, stderr and stdout to communicate with the Spawner. The protocols are very similar.
A preloader initializes in 4 stages:
-
It first goes through a handshake, which is the same as the loader handshake.
-
It loads the application just like the loader does.
-
It sets up a server on which it listens for spawn commands.
-
It sends a response back to the Spawner. This is similar to how the loader does it, but instead of telling the Spawner where the application listens for requests, it tells the Spawner where the preloader process listens for spawn commands.
Once initialized, the preloader enters a main loop, in which it keeps handling spawn commands until a signal has been received that says it should terminate.
When a spawn command is received, the preloader forks off a child process (which already has the application loaded) and reports the child process’s PID to the Spawner. It also sets up a communication channel between the Spawner and the child process.
4.4. The AppTypes registry
When the web server receives a request, the Phusion Passenger module inside it autodetects the type of application that the request belongs to. It does that by examening the filesystem and checking which one of the startup files exist. For example, if config.ru exists, then it assumes that it’s a Ruby app. Or if app.js exists, then it assumes that it’s a Node.js app. The Phusion Passenger module forwards the inferred application type to the Passenger core.
Given an application type, the associated loader and preloader can be looked up.
Information about the supported application types, startup files, loaders and preloaders are defined in the following places:
-
The constant appTypeDefinitions in the file ext/common/ApplicationPool2/AppTypes.cpp keeps a list of supported languages. It also specifies the default startup file name belonging to each language.
-
The method getStartCommand() in the file ext/common/ApplicationPool2/Options.h defines the loaders that should be used for each language.
-
The method tryCreateSmartSpawner() in the file ext/common/ApplicationPool2/SpawnerFactory.h defines the preloaders that should be used for each language.
-
The method looks_like_app_directory? in the file lib/phusion_passenger/standalone/app_finder.rb keeps a list of supported startup files. This is only used within Passenger Standalone.
5. Instance state and communication
Every time you start Phusion Passenger, you’ve created a new instance. Every instance consists of multiple processes that work together (Watchdog, Passenger core, UstRouter, application processes). All those processes have to be able to communicate with each other. Those processes must also not communicate with the processes belonging to other instances. For example, if you start Apache+Passenger and Nginx+Passenger, then we don’t want the Passenger core that’s started from Apache to use UstRouter that’s started from Nginx.
Clearly, the processes can’t listen on a specific TCP port for communication. Nor can they listen on a fixed Unix domain socket filename.
That is where the instance directory comes in. Every Phusion Passenger instance has its own, unique temporary directory. That directory is removed when the instance halts. The directory contains Unix domain socket files that the processes listen on. Every Phusion Passenger related process knows where its own instance directory is, and thus, knows how to communicate with other processes belonging to the same instance. The instance directory is implemented in ext/common/InstanceDirectory.h.
Administration tools such as passenger-status query information using instance directories. First, they check which instance directories exist on the system. If they find only one, then they query the sockets inside that sole instance directory. Otherwise, they abort with an error and ask the user to specifically select the instance to query.
6. Appendix A: About Rack
The de-facto standard interface for Ruby web applications is Rack. Rack specifies an programming interface for web application developers to implement. This interface covers HTTP request and response handling, and is not dependent on any particular application server. The idea is that any Rack-compliant application server can implement the Rack specification and work with all Rack-compliant web applications.
In the distant past, each Ruby web framework had its own interface, so application servers needed to explicitly add support for each web framework. Nowadays application servers just support Rack.
Ruby on Rails has been fully Rack compliant since version 3.0. Rails 2.3 was partially Rack-compliant while earlier versions were not Rack-compliant at all. Phusion Passenger supports Rack as well as all Rails 1.x and 2.x versions.
7. Appendix B: About Apache
The Apache web server has a dynamic module system and a pluggable I/O multiprocessing (the ability to handle more than 1 concurrent HTTP client at the same time) architecture. An Apache module which implements a particular multiprocessing strategy, is called a Multi-Processing Module (MPM). The single-threaded multi-process prefork MPM had been the default and the most popular one for a long time, but in recent times the hybrid multi-threaded/multi-process worker MPM is becoming increasingly popular because of its better performance and scalability. Furthermore, Apache 2.4 introduced the event MPM which is a hybrid evented/multi-threaded/multi-process MPM and offers even more scalability benefits.
The prefork MPM remains in wide use today because it’s the only MPM that works well with mod_php.
The prefork MPM spawns multiple worker child processes. HTTP requests are first accepted by a so-called control process, and then forwarded to one of the worker processes. The next section contains a diagram which shows the prefork MPM’s architecture.
8. Appendix C: About Nginx
Nginx is a lightweight web server that is becoming increasingly popular. It is known to be smaller, lighter weight and more scalable than Apache thanks to its evented I/O architecture. That said, Nginx is less flexible than Apache. For example it has no dynamic module system: all modules must be statically compiled into Nginx.